It has been almost an year since I joined Suki. We build AI-powered voice solutions for healthcare and are on a mission to help doctors focus on what matters.
In this post on the Suki blog, I share why I feel lucky to be working with a passionate group of people that truly care about Suki’s values and make them part of the way they work.
For the longest time, I have been interested in learning to fly. Like most kids, I wanted to fly planes when I was younger. During the last few years, I found myself to be hooked to the aviation channels on YouTube which ended up furthering my resolve to check out a flight school. This last month, I did my first solo flight where I was flying the plane on my own without the security of an instructor on the next seat.
I finally took the plunge earlier this year and went on my discovery flight. A discovery flight is a short session where you get to experience firsthand what it means to fly a plane. You go out with an instructor who lets you do simple maneuvers, such as making turns, etc. The idea is that this first experience would let you decide on whether learning to fly is something that you’d like to pursue further. I promptly applied for a student license and got my medical Exam done to begin my training.
In this post, I put down my thoughts so far on my process of learning to fly and share what I learned about myself during this training.
All smiles after the first solo and completing my three touch and goes.
Training the body
Increasing the angle of attack usually results in increased lift making the plane gain altitude, but increasing it beyond the critical angle causes it to stall. Plane by osmosikum is licensed under Creative Commons Attribution.
One of the first few maneuvers that a student pilot learns is recovering from a stall. The wings of the airplane produce lift when there is smooth airflow over them. This lift usually increases either with the relative wind speed as the plane goes faster, or when the angle at which the wing meets the relative wind is increased when the pilot pulls up on the yoke. This angle is known as the angle of attack. However, there is a limit to which the pilot can increase the angle of attack. If we increase this angle of attack beyond a critical angle then the wind no longer flows smoothly over the wing and it stops producing the lift that keeps the plane flying. This is known as stalling of the wing and the plane starts to lose altitude. The only way to recover from this situation is to reduce the angle of attack by pressing the yoke forward to pitch down. This can be a bit counter-intuitive for new student pilots since they wanted the stalled plane stop losing altitude in the first place.
There is an interesting phenomenon that I learned about myself while trying out this procedure for the first time. I learned about the disconnect between what I thought and the action that my body wanted to do. Before going for the flight, I had studied the theoretical concepts behind the maneuver. My instructor even demonstrated the procedure before having me go at it. However, when I actually tried the exercise for the first time something strange happened. Instead of pushing the yoke down to reduce the angle of attack of the wing, every cell of my body wanted to pull up on the yoke to maintain altitude. It took immense willpower to do the right thing, i.e., to push the yoke down. Following the natural instinct of my ground-dwelling body would have certainly made the matters worse. The plane would continue to be stalled and would rapidly lose altitude. This was especially concerning since I was prepared for what was happening and intellectually convinced myself about why pushing the yoke down was the correct course of action. Things would have been drastically more demanding in a situation if a stall were to happen inadvertently (vs. in a practice maneuver). In fact, if a training plane were to be left on its own it would most likely recover on its own from a stall. Yet, stall and spin accidents do happen. Investigation often later reveal that the pilot continued pulling up instead of reducing the angle of attack.
I learned the importance of training the body and getting used to the sensations felt by the body before an impending stall. It most certainly not my first time experiencing this kind of disconnect, but this one was an ‘in your face’ kind of situation. One that was difficult to ignore— my intellect seemed to have been overruled by the body. I was able to spend time analyzing and deconstructing what happened on the drive back home. I realized the importance of training the body until the natural thing to do would be the right course of action. And this training happens by practice and repetition. Again and again.
The Aha! moments
Like most student pilots, I would undergo a sensory overload when flying the plane at the beginning of every new training lesson. There is a lot of multitasking that goes on while piloting a plane. You need to follow the checklists, scan through a several instruments, look for other traffic in the sky, make radio calls, understand how the plane is reacting to various control inputs, and also corroborate these practical observations with the theoretical concepts learned from the textbook. Everything would appear to happen so quickly that you barely have time to follow what your instructor is saying from the adjacent seat. Over the course of the training, time almost starts to slow down and one can handle more tasks. This process, however, doesn’t appear to be a linear one. I had periods where I would struggle with a concept only to have a sudden aha! moment when everything would seem to click. This was most evident while learning how to land the plane.
Landings are supposed to be tricky for most new pilots. So much seems to be happening at the same time. There is a lot of material out there teaching what is needed for a good landing. Even your instructor would also probably tell you those same things over and over again on multiple landing attempts. Yet, everyone struggles with landings in the beginning until when things suddenly start falling into their place. This is what I am referring to as an aha! moment in learning. It is not to say the I had perfect landings after this point but I would be able to debug what went wrong in a step-by-step manner. In contrast, my first few landings would be a complete blur and I wouldn’t be able to describe what went by.
The job of a good teacher here is to be able to break down the lesson into smaller steps that can be grasped by the student. Hearing the same instruction in slightly different wordings was also helpful to me here. The task of learning was to deconstruct the various phases of landing and be able to diagnose how to refine each step when things didn’t happen in an ideal way.
These were some of my learnings from the flight training so far that I think have applications beyond flight school. I still have a long way to go in flight school and hope to keep you posted on what and how I learn in the future! Let me know what you think about these thoughts.
Typing Sanskrit can be challenging if you don’t have access to your special keyboard, or don’t have your favorite input tools installed on the computer you are working on.
So I set out to write a Google Docs add-on that could make it easy to do so. A Google Docs add-on could be an ideal option for typing Sanskrit, even while using guest computers.
Sanskrit has more sounds than English and other languages written in Roman scripts. Devanagari is the commonly used script used for writing Sanskrit and uses non-ASCII characters. Some systems such as IAST and ITRANS use additional symbols to represent Sanskrit sounds in Roman-like scripts. For example, ā in IAST is used to represent the long “a” syllable.
I found this library called Sanscript.js which could convert between these different writing schemes. However it doesn’t address the problem of being able to use a standard keyboard with ASCII characters. IAST includes additional characters such as ū, ṣ, ñ, ṅ, ṃ, etc. It is more readable than other competing schemes such as ITRANS. ITRANS includes a mix of upper-case and lower-case letters, in the middle of a word, to represent additional sounds. This has adverse affect on the aesthetics of the script. I find it harder to read as well. IAST has also been used in academia and Sanskrit books written in the West since a long time. As a result many users of Sanskrit language are familiar with this system. It was later standardized as ISO 15919 with small changes.
I added a new “IAST Simplified” scheme to the list supported by Sanscript.js. This is inspired from my favorite Sanskrit writing software called Sanskrit Writer. This scheme uses standard ASCII characters and closely resembles the IAST scheme. For example, it uses –a for ā,~n for ñ, and h. for ḥ, and so on. The following table explains this scheme in detail:
Vowels
अ
a
आ
-a
इ
i
ई
-i
उ
u
ऊ
-u
ऋ
r.
ॠ
-r.
ऌ
l.
ॡ
-l.
ए
e
ऐ
ai
ओ
o
औ
au
ं
m.
ः
h.
Consonants
क
ka
ख
kha
ग
ga
घ
gha
ङ
.na
च
ca
छ
cha
ज
ja
झ
jha
ञ
~na
ट
t.a
ठ
t.ha
ड
d.a
ढ
d.ha
ण
n.a
त
ta
थ
tha
द
da
ध
dha
न
na
प
pa
फ
pha
ब
ba
भ
bha
म
ma
श
‘sa
ष
s.a
स
sa
ह
ha
ळ
_la
य
ya
र
ra
ल
la
व
va
Vowel Marks
क्
k
खा
kh-a
गि
gi
घी
dh-i
ङु
.nu
चू
c-u
छृ
chr.
जॄ
j-r.
झॢ
jhl.
ञॣ
~n-l.
टे
t.e
ठै
t.hai
डो
d.o
डौ
d.au
थ
tha
णं
n.am
तः
tah.
क्ष
ks.a
त्र
tra
ज्ञ
j~na
Symbols
ऽ
‘
।
.
।।
..
०
0
१
1
२
2
३
3
४
4
५
5
६
6
७
7
८
8
९
9
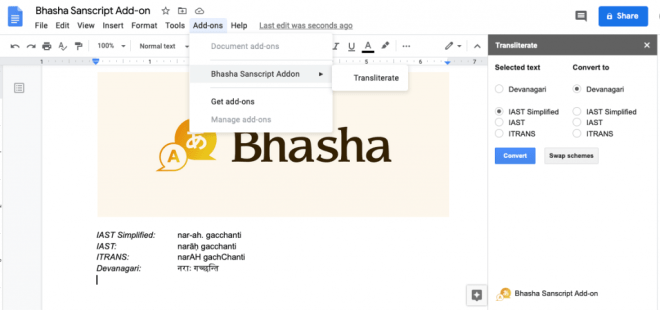
After these additions to Sanscript.js, I was able to write a quick Google Docs plugin that could convert between different schemes with a click of a button. You can try this plugin out by visiting this link, or searching for “Bhasha” in Google Docs under addons.
I was hoping to have a WYSIWYG design where transliteration could happen as you typed. This required intercepting each edit, and was not possible using the Google Docs API. As a second option, I wrote a plugin for QuillJS, a cool open-source rich-text editor. You can try out this add-on here: https://trivedigaurav.com/exp/bhasha/.
Screenshot of the QuillJs editor with Bhasha plugin.
This may not be mobile friendly. I didn’t spend time test it on the phone since you can easily switch to a Sanskrit keyboard on a phone anyway.
Source code for the QuillJS plugin is on Github here. Please feel free to hack on it!
We are seeing a rise of Artificial Intelligence in medicine. This has potential for remarkable improvements in diagnosis, prevention and treatment in healthcare. Many of the existing applications are about rapid image interpretation using AI. We have many open opportunities in leveraging NLP for improving both clinical workflows and patient outcomes.
Python has become the language of choice for Natural Language Processing (NLP) in both research and development: from old school NLTK to PyTorch for building state-of-the-art deep learning models. Libraries such as Gensim and spaCy have also enabled production-ready NLP applications. More recently, Hugging Face has built a business around rapidly making current NLP research quickly accessible.
Yesterday, I presented on processing clinical text using Python at the local Python User Group meeting.
During the talk I discussed some opportunities in clinical NLP, mapped out fundamental NLP tasks, and toured the available programming resources– Python libraries and frameworks. Many of these libraries make it extremely easy to leverage state-of-the-art NLP research for building models on clinical text. Towards end of the talk, I also shared some data resources to explore and start hacking on.
It was a fun experience overall and I received some thoughtful comments and feedback — both during the talk and later also online. Special thanks to Pete Fein for organizing the meetup. It was probably the first time I had so many people put on a waitlist for attending one of my presentations. I am also sharing my slides from the talk in hope that they can be useful…
I was recently interviewed by my fellow ISP student, Huihui Xu, about my experience with the Intelligent Systems Program at Pitt. Huihui served as the editor of 2019 Intelligent Systems Program Newsletter. With her permission, I am posting an adapted version of her article here. I started this blog during the first week of my PhD program. I reflect on my journey in this post.
On how I picked my dissertation topic and why I think it was important…
While preparing my statement of purpose for the PhD program, I had plans to work on AI systems that work in collaboration with human experts. I was interested in Human-Computer Interaction and Intelligent Interfaces in general at that time.
I had an opportunity to join a project team with Drs. Hochheiser (my PhD advisor), Wiebe, Hwa, and Chapman during the first year of my program. Later, members from this project also served on my committee.
We explored methods for incorporating clinician (human) feedback to build Natural Language Processing models. The project helped me form the core idea of my dissertation: Interactive Natural Language processing for Clinical Text.
Current approaches require a long collaboration between clinicians and data-scientists. Clinicians provide annotations and training data, while data-scientists build the models. The domain experts do not have provisions to inspect these models or give direct feedback. This forms a barrier to NLP adoption limiting its power and utility for real-world clinical applications.
In my dissertation "Interactive Natural Language Processing for Clinical Text" (Trivedi, 2019), I explored interactive methods to allow clinicians without machine learning experience to build NLP models on their own. This approach may make it feasible to extract understanding from unstructured text in patient records; classifying documents against clinical concepts, summarizing records and other sophisticated NLP tasks while reducing the need for prior annotations and training data upfront.
On obstacles to my dissertation…
One challenge I faced during the middle of my dissertation was identifying further clinical problems (and data) where I could replicate the ideas defined in my first project.
Pursuing my PhD program in the Intelligent Systems Program allowed me to form good collaborations at Department of Biomedical Informatics, with Dr. Visweswaran’s group, as well as clinicians from University of Pittsburgh Medical Center. Dr. Handzel, who is a Trauma surgeon, served as a teaching assistant for my Applied Clinical Informatics course at DBMI. I was able to discuss my ideas for insights on clinical problems that I could work on. He also got on board to develop the ideas further. We worked on building an interactive tool for "Interactive NLP in Clinical Care: Identifying Incidental Findings in Radiology Reports" (Trivedi et.al., 2019):
During initial validation of my ideas, I even had a chance to shadow trauma surgeons in the ICU. These collaborations not only made it easier to get access to the required data, but also run my evaluation studies with physicians as study participants.
On Intelligent Systems Program…
ISP is an excellent program for applied Artificial Intelligence. The founders were definitely visionaries in starting a program dedicated for AI applications over thirty years ago. Now everybody is talking about using machine learning (and more recently deep learning) for applications in medicine & health, education and law. ISP provides an environment for interdisciplinary collaboration. Clearly, I benefited a lot from these collaborations for my dissertation.
I participated in BlueHack this weekend – a hackathon hosted by IBM and AmerisourceBergen. I got a chance to work with an amazing team (Xiaoxiao, Charmgil, Hedy, Siyang and Michael) — the best kind of team-members you could find at a hackathon. We were mentored by veterans like Nick Adkins (the leader of the PinkSocks tribe!), whose extensive experience was super-handy during the ideation stage of our project.
Our first team-member, Xiaoxiao Li, is a Dermatology resident who came to the hackathon with ideas for a dermatology treatment app. She explained how most dermatology patients come from a younger age-group and are technologically savvy enough to be targeted with app-based treatment plans. We bounced some initial ideas with the team and narrowed down on a treatment companion app for the hackathon.
We picked ‘acne’ as an initial problem to focus on. We were surprised by the billions of dollars that are spent on acne treatments every year. We researched the main problem in failed treatments to be patient non-compliance. This happens when the patients don’t understand the treatment instructions completely, are worried about prescription side-effects, or are just too busy and miss doses. Michael James designed super cool mockups to address these issues:
While schedules and reminders could keep the patients on track, we still needed a solution to answer patients’ questions after they have left the doctor’s office. A chat-based interface offered a feasible solution to transform lengthy home-going instructions into something usable, convenient and accessible. It would save calls to the doctor for simpler questions, while also ensuring that patients clearly understand doctor’s instructions. Since this hackathon was hosted by IBM, we thought that it would be prudent to demo a Watson-powered chatbot. Charmgil Hong and I worked on building live demos. Using a fairly shallow dialogue tree, we were able to build a usable demo during the hackathon. A simple extension to this would be an Alexa-like conversational interface, which can be adopted for patient-education in many other scenarios such as post-surgery instructions etc.:
Hedy Chen and Siyang Hu developed a neat business plan to go along as well. We would charge a commitment fee from the patients to use our app. If the patients follow all the steps and instructions for the treatment, we return a 100% of their money back. Otherwise, we make money from targeted skin-care advertisements. I believe that such a model could be useful for building other patient compliance apps as well. Here‘s a link to our slides, if you are interested. Overall, I am super happy with all that we could achieve within just one and a half days! And yes, we did get a third prize for this project 🙂
This is a followup on my earlier post on Machines Learn to play Tabla. You may wish it check it out first reading this one…
Three years ago, I published a post on using recurrent neural networks to generate tabla rhythms. Sampling music from machine learned models was not in vogue then. My post received a lot of attention on the web and became very popular. The project had been a proof-of-concept and I have wanted build on it for a long time now.
This weekend, I worked on making it more interactive and I am excited to share these updates with you. Previously, I was using a proprietary software to convert tabla notation to sound. That made it hard to experiment with sampled rhythms and I could share only a handful sounds. Taking inspiration from our friends at Vishwamohini, I am now able to convert bols into rhythm on the fly using MIDI.js.
Let me show off the new javascript synthesizer using a popular Delhi kaida. Hit the ‘play’ button to listen:
Now that you’ve heard the computer play, here’s an example of it being played by a tabla maestro:
Of course, the synthesized outcome is not much of a comparison to the performance by the maestro, but it is not too bad either…
Now to the more exciting part- Since our browsers have learned to play the tabla, we can throw in the char-rnn model that I built in the earlier post. To do this, I used the RecurrentJS library and combined it with my javascript tabla player:
Feel free to play around with tempo and maximum character-limit for sampling. When you click on ‘generate’, it will play a new rhythm every time. Hope you’ll enjoy playing with it as much as I did!
The player has a few kinks at this point I am working towards fixing them. You too can contribute to my repository on GitHub.
There are two areas that need major work:
Data: The models that I trained for my earlier post was done using a small amount of training data. I have been on a lookout for better dataset since then. I wrote a few emails, but without much success till now. I am interested in knowing about more datasets I could train my models on.
Modeling: Our model did a very good job of understanding the structure of TaalMala notations. Although character level recurrent neural networks work well, it is still based on very shallow understanding of the rhythmic structures. I have not come across any good approaches for generating true rhythms yet:
Do any ML poetry generators do rhyme or meter yet? Seems like a hard feature to model/train (compared to a grammar or constraint approach, etc)
I think more data samples covering a range of rhythmic structures would only partially address this problem. Simple rule based approaches seem to outperform machine learned models with very little effort. Vishwamohini.com has some very good rule-based variation generators that you could check out. They sound better than the ones created by our AI. After all the word for compositions- bandish, literally derived from ‘rules’ in Hindi. But on the other hand, there are only so many handcrafted rules that you can come up with which may lead to generating repetitive sounds.
Contact me if you have some ideas and if you’d like to help out! Hope that I am able to post an update on this sooner than three years this time 😀